
Easy K8S Connectivity for Local Utils
With the new targetless mode of mirrord, you can run a program locally on your machine, and mirrord will forward network connections initiated by the program to the cluster, such that the program gets the connectivity it would have if it were deployed to the cluster. Together with the secret sauce of in-cluster DNS resolution, you can run a program on your computer and have it access cluster-internal services that do not have any external IP. The program would also have access to third-party services that are open to IPs from your cluster, but not to your local IP.
This can be useful for different cases, notably for running utility tools with access to the cluster, or for debugging new services.
Running utility programs with access to your cluster
When you run an application with mirrord, and the application connects to a network address or domain name, DNS resolution as well as the network connection will be done from the cluster. This lets you run tools locally for configuring or testing your services on the cluster.
Let’s see what this looks like with a little practical example. We have a Kafka cluster set up on Kubernetes1:


With mirrord we can use utility tools to manage and test the services on the cluster, with the same ease as if they
were running locally. Say we want to read some events from an existing weather-updates topic. We just run Kafka’s
console client, and give it the name of the bootstrap service as its URL.
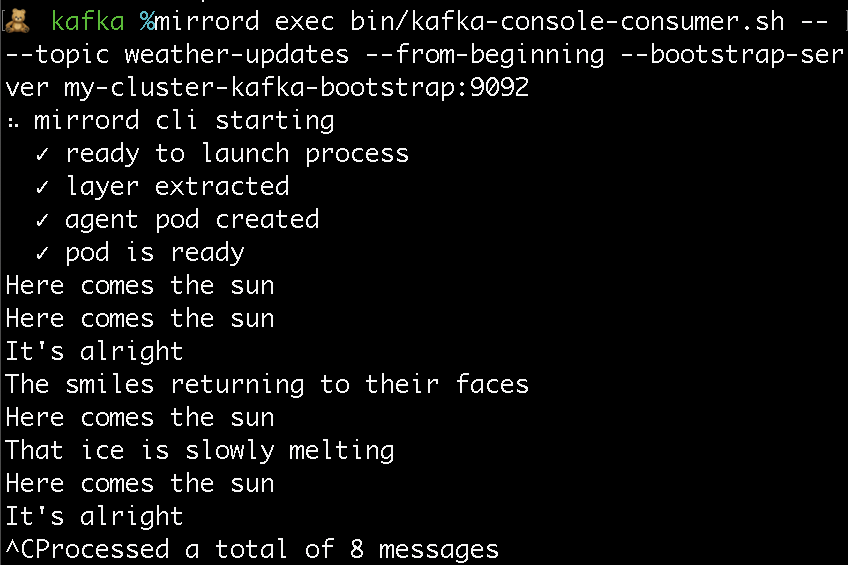
The client connects to the bootstrap server, which tells it what Kafka brokers it should connect to, and it then fetches the events from those brokers.
All of this works with a simple client running locally on the developer’s machine. No containerizing, no deployment, no setup. And the fun part is mirrord operates on the process level, so it doesn’t affect connectivity for the rest of your system. This means you can even run multiple applications accessing different clusters or different namespaces at the same time.
Access external services through the cluster
When you run an application with mirrord, the connections it initiates will be sent out of a temporary pod on your Kubernetes cluster. This means your application can connect not only to services in the cluster, but to any endpoint in the internet that the cluster has access to. This can be useful if you want your application to communicate with external services that are configured to only accept communication from your cluster’s IP address, or if you want to test your cluster’s network connectivity to external services.
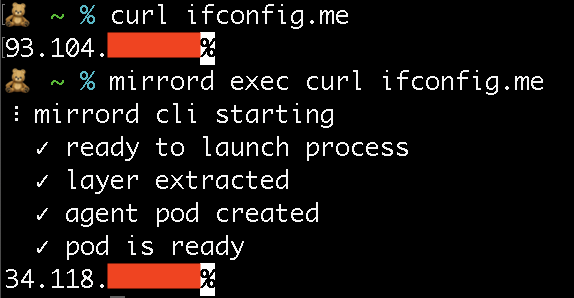
In the screenshot below you can see what it looks like when we run curl ifconfig.me (a web service that returns
the IP you connect from in its response) with mirrord (IPs partially redacted). When we run the curl command with
mirrord, it’s sent out of the cluster, so the cluster’s egress IP is returned.
Debugging new services with targetless mirrord
Your microservices are deployed on the cluster, so far away. You can see they are there with kubectl. You can even port-forward to them. But if you are working on a brand-new microservice that communicates with your existing microservices, you can’t run it locally, because its requests to the other microservices will fail, especially if addressed by cluster-internal domain names. So close, and yet so far. So in order to test your new little service which barely even does anything, you have to create Kubernetes resources for it, package it in a container, deploy it to the cluster, right?
Wrong, obviously.
Just run it with mirrord, and when it makes requests to services on the cluster, they’ll just work. The DNS
resolving will be performed on your cluster, and the network traffic will be emitted from within your cluster, so
your new little app won’t even notice that it’s running locally and not deployed to the cloud. You can run your app
either from your IDE (VS Code/IntelliJ-based IDEs) using the mirrord extension, or from the command line, with
mirrord exec [mirrord-options …] <YOUR-APP> [-- app-args …]. You can iterate through changes in your application,
rerunning it easily after each little change, and even set breakpoints in your IDE and debug your application,
while it is communicating as if it is running in your cluster.
Why is it called “targetless”?
“Targetless” is a new mode for mirrord, which up until now always had to have a target to operate. In the normal mode of operation of mirrord, you specify a target container on your cluster (you can specify it by the pod or even the deployment, you do not have to know the specific container name). mirrord then spawns an agent on the same node as the target, which helps your local program impersonate that container - mirror or steal its incoming traffic, send out network requests over it, access the same filesystem and read its environment variables.
The main use case for this mode is to debug a new version of an existing application. For example, if you are making changes to an API endpoint of an existing microservice, you can run the changed version with mirrord, with the existing microservice running in the cloud as a target, and when that service receives requests, they will be mirrored (or redirected entirely) to your local application by mirrord. This lets you debug the changed endpoint using traffic from the Kubernetes cluster without deploying a new version after every little change.
Can’t I just use kubectl port-forward?
There are some basic tasks that can be achieved with either mirrord or kubectl port-forward in varying degrees of comfort. However, mirrord does something fundamentally different from port-forwarding. mirrord runs an application and forwards to the cluster whatever connections it initiates. This means you don’t need to know the ports in advance and configure them before running the application, DNS is resolved in the cluster, UDP is forwarded as well as TCP, and connections can also be made to addresses outside the cluster (with the source address of the cluster, so if an external service is only open to the cluster’s IP, the application can access it with mirrord).
I want to start using it right now!
Look at you, trying out new things, learning every day. Good for you. Installing the mirrord CLI tool is as easy as running
brew install metalbear-co/mirrord/mirrord
or
curl -fsSL https://raw.githubusercontent.com/metalbear-co/mirrord/main/scripts/install.sh | bash
Or you can install it as a VS Code extension or a plugin for IntelliJ-based IDEs.
Of course, as mirrord is completely open source you can also build it from source.
Check out the mirrord docs, especially the mirrord configuration docs, and the target reference for how to run targetless. Reach out to us on Discord or GitHub for help, questions, feedback or just to say hi.
We used the manifests from Red Hat Developer’s Kafka in Kubernetes tutorial to quickly set up the cluster. ↩︎

