
Split Queues To Share Cloud Development Environments
One of the reasons mirrord for Teams is a gamechanger for many organizations is that it makes it possible for a whole team to work with one shared cloud environment. They don’t need to run the whole environment for each developer, they don’t need to have their entire architecture running on their laptops, and they don’t need to redeploy to Kubernetes to test new code or debug it. Developers just press “run” in their IDE, and their code is executed remocally: the code runs locally, but with access to any required resources in the Kubernetes cluster or outside of it. With mirrord for Teams, developers can even work on the same service at the same time, and control how to divide between them consumable data like incoming HTTP requests, and now also queue messages.
Remote queue messages can be divided between local processes using a new feature called queue splitting. With queue splitting, developers can configure queue message filters for their mirrord session, and their application will only receive messages that match the filters when it fetches messages from a queue. That way, developers can generate test messages, and know for sure it’s the application running in their IDE that will receive those messages. Additionally, their application will only read messages intended for it, leaving the rest to be read by the remote service (or other developers), and avoiding disruption of the shared environment. The first supported queue service is Amazon Simple Queue Service, with support for Apache Kafka and RabbitMQ coming soon.
How Queue Splitting Works In a Nutshell
In order to enable queue splitting, there is some initial setup ( explained in the documentation) that has to be done by someone with the appropriate permissions for the Kubernetes cluster and the AWS account. Once that is set up, developers can set their filters in their mirrord configuration file and start mirrord runs with queue splitting. For now, the application reading from the queue has to define the name of the queue it reads from in an environment variable defined directly in the Kubernetes deployment definition or in the Argo rollout. When a session starts, the mirrord operator will create new temporary queues, and change the environment variables visible to the local and to the deployed application, such that they each use a different queue. The mirrord operator then consumes messages from the original queue instead of the deployed application, and forwards them to the appropriate temporary queue depending on the defined filters. When a mirrord run ends, the temporary queue created for it is deleted. Once all mirrord runs that split a certain queue end, the temporary queue created for the deployed application is also deleted.
A Two-User-Story
To make the use-case for this feature a bit more concrete, let’s think about a team developing this example project with multiple microservices, deployed on Kubernetes. In that project, there is a service called ip-visit-counter that writes a message to an SQS queue every time it gets a request. The service ip-visit-sqs-consumer reads messages from that queue.

If Amy wants to test a new version she’s working on, where ip-visit-counter sends messages with a changed format,
she can run that service locally with mirrord, make it set the message attribute "x-pg-tenant: Amy" to all
messages it creates, and run her changed ip-visit-sqs-consumer with a filter ”x-pg-tenant”: ”^Amy$” for the queue.
In order to do that, she adds this setting to her mirrord configuration file:
{
"feature": {
"split_queues": {
"ip-count": {
"queue_type": "SQS",
"message_filter": {
"x-pg-tenant": "^Amy$"
}
}
}
}
}
That way, the application running locally in her IDE gets all the messages she generates for it, and only those messages. The deployed application does not receive any of those messages. She can set breakpoints and debug how her application handles those queue messages.
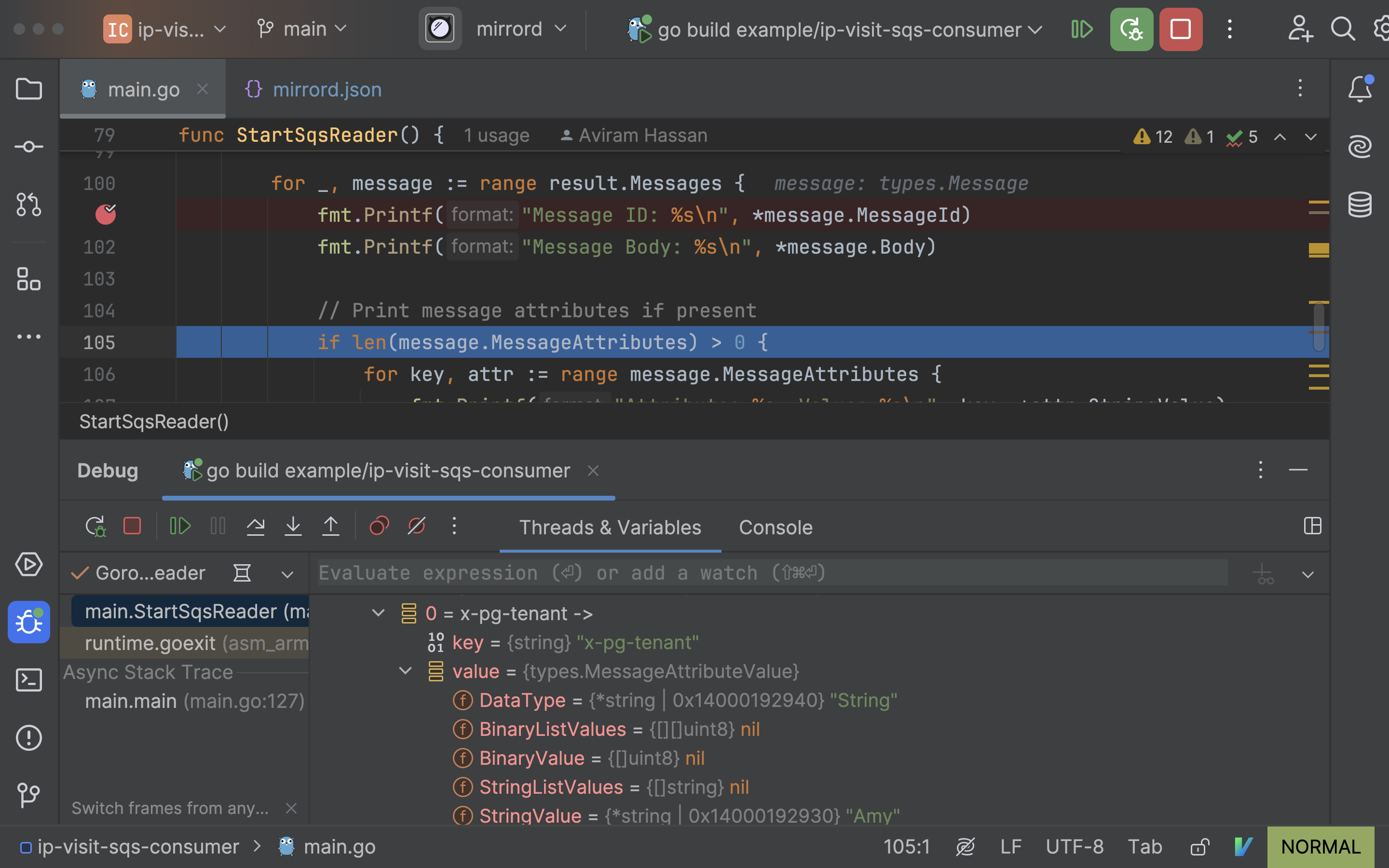
The deployed application does receive messages not generated by Amy’s changed producer, so Amy does not disrupt the shared environment.
Now let’s say Bruno, Amy’s teammate, wants to work on some bug fix for the consumer service. He would also like the
application he’s running locally to read messages from the queue. Bruno can just set his own filter (e.g.
”x-pg-tenant”: ”^Bruno$”) in his mirrord configuration file, make sure the messages he generates for debugging
match that filter, and work on the same service at the same time, consuming messages from the same queue. Behind
the scenes, this is what the setup looks like while Amy and Bruno are splitting the queue:

Try It Out, Stay In Touch
If you want to try out SQS splitting, but don’t yet have mirrord for Teams, just register for a free trial. It does not require a payment method, and it does not automatically extend if you don’t get a subscription. And if you would like to talk to us, feel free to write to us at [email protected], or to join our Discord server.

